“High-Frequency Component Helps Explain the Generalization of Convolution Neural Networks”发表于CVPR 2020,主要是从频率的角度分析CNN到底在提取什么特征,以及图片的高频部分和低频部分 对CNN泛化能力的影响。
The Misalignment Between CNN and Human
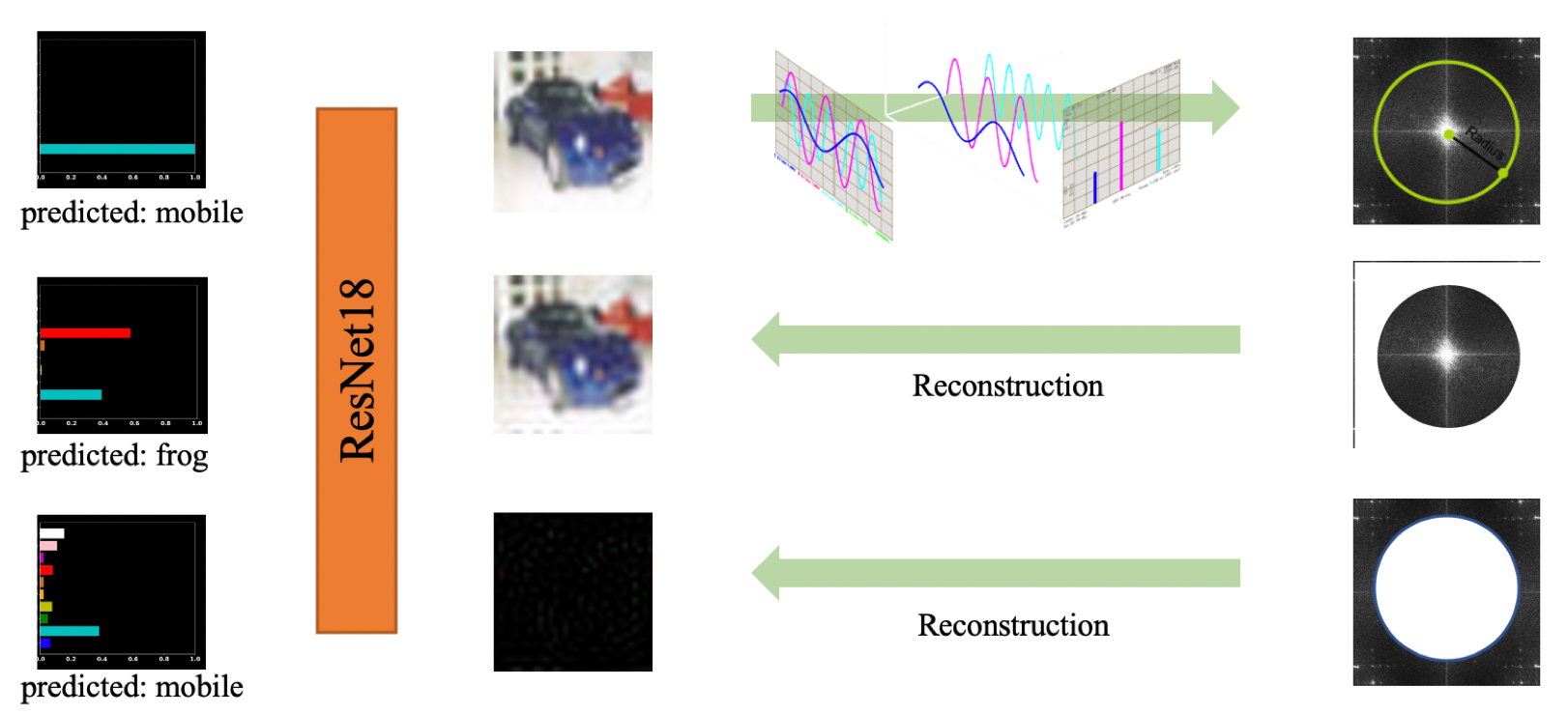
在上图中,第一行是原始图片,经过傅里叶变换后,取中间部分作为低频部分,四周为高频部分。低频和高频部分分别恢复为图片,低频部分和原始图片非常相似,但是模型错误的把它预测成了青蛙;高频部分完全看不出来是什么,但是模型却能分类正确。
 作者认为在人类眼中,只有低频部分和label存在关系,而模型却既学习了低频部分也学习了高频部分,因此人类常常难以理解模型的某些行为,例如对抗样本。
作者认为在人类眼中,只有低频部分和label存在关系,而模型却既学习了低频部分也学习了高频部分,因此人类常常难以理解模型的某些行为,例如对抗样本。
Trade-off between Robustness and Accuracy
Assumption 1: only $x_l$ is perceivable to human, but both $x_l$ and $x_h$ are perceivable to a CNN.
As a result, CNN’s generalization behavior appears unintuitive to a human.
Assumption 2: for model θ, there exists a sample ⟨x, y⟩ such that:
根据假设一二,我们可以得到推论:
总存在一个样本$<x,y>$,使得模型不能准确鲁棒地分类。

LFC & HFC
In the original label case, the model will first pick up LFC , then gradually pick up the HFC to achieve higher training accuracy.
In the shuffled label case, as the association between LFC and the label is erased due to shuffling , the model has to memorize the images when the LFC and HFC are treated equally.

Since the data sets are organized and annotated by human, the LFC-label association is more “generalizable” than the one of HFC.

分别用低频部分和高频部分来训练模型
随着r变大,由于保留的高频成分越多,所以训练集和测试集准确率都增加了,这其实说明高频成分不全是噪声,其中包括一些和数据分布相关的有用信息
采用低频成分训练的泛化能力远远高于高频成分训练的模型。这个现象造成的原因是label是人类标注的,人类本身就是按照低频语义信息进行标注
Robust Models Have Smooth Kernels

作者认为对抗样本是扰动了人类看不到的高频成分,从而使得模型无法识别。
首先采用标准的FGSM或者PGD等方法生成对抗样本,然后将对抗样本联合原始数据进行训练,最后可视化第一次卷积核参数,
可以发现经过对抗样本训练后的模型,卷积核参数更加平衡(相邻位置的权重非常相似)。(a)和(b)
作者猜想:也许直接把卷积核平滑化可以提高鲁棒性
将(a)和(b)分别按右上角公式平滑,得到(c)和(d)

平滑之后,准确率下降了许多,但是鲁棒性有所提高
一些启发
本文观察的角度还是很有意思的,人类作为ground-truth classifier,其实只考虑了数据的某些特征。也就是
$$
G(x) = g(f(x))
$$
其中$G(x)$表示人类,$f$在本文中为低通滤波器。
那么一个非常自然的问题是: What is the best choice of f? Can we learn it?
另外,$f$可能和预处理方法有关。