1 什么是机器学习
1.1 从学习到机器学习
学习:获取技术,从观察中积累得到经验
观察 -> 学习 -> 技巧
机器学习:获取技术,从数据中积累/计算得到经验
数据 -> 机器学习 -> 技巧
所以到底什么是技巧呢?
1.2 一个更具体的定义
技巧 <-> 增进某一种表现(比如:预测的精确度)
机器学习:增进某一种表现,从数据中积累/计算得到经验
数据 -> 机器学习 -> 增进某一种表现
2 为什么要用机器学习
机器学习:让机器自己学习
简单来说,就是两大原因:
一些数据或者信息,人来无法获取,可能是一些人无法识别的事物,或是数据信息量特别大;
另一个原因是人的处理满足不了需求,比如:定义很多很多的规则满足物体识别或者其他需求;在短时间内通过大量信息做出判断等等。
一些应用场景:
- 当人们不容易手动的编写程序时;
- 规则不容易定义时;
- 需要以极快的速度作出判断时;
- 一个应用需要对非常多的用户进行个性化服务时。
相当于对电脑“授之以渔,而非授之以鱼”
3 机器学习的关键要素
- 存在一些“潜在的模式”可以被学习
- 但是规则不容易被定义
- 有数据
以上三个要素都有,才有可能使用机器学习
4 一个例子
银行要不要发信用卡给某个顾客
顾客资料:
| age | 23 years |
|---|---|
| gender | female |
| annual salary | NTD 1,000,000 |
| year in residence | 1 year |
| year in job | 0.5 year |
| current debt | 200,000 |
5 机器学习的抽象化表示
抽象化:
- 输入:$x \in X$ (客户申请)
- 输出:$y \in Y$ (提供信用卡后好 / 坏)
- 现在不知道但是希望机器学习学到的东西(目标函数):
$f:X \to Y$ (理想的信贷审批公式) - 数据:$D={(x_1,y_1),(x_2,y_2),…,(x_N,y_N)}$ (银行的历史记录)
- 假说(有良好性能的 skill):
$g:X \to Y$ (机器学习学到的东西)
总结下来就是:
$${(x_n,y_n)} ; from ; f \to \fbox{ML} \to g$$
更详细的流程: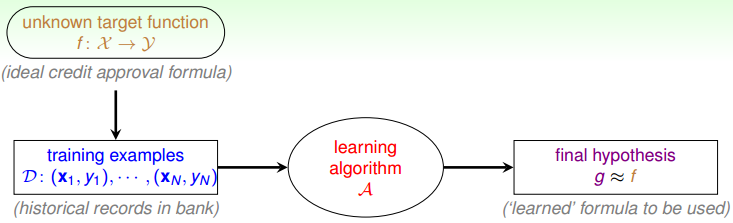
从左上角开始,理想公式 f 产生资料(这个过程是不知道的),把资料喂给机器学习演算法(机器学习的核心),最后机器学习告诉我们结果(我们希望 g 和 f 越像越好)
需要强调的两件事:
- f 是未知的
- 希望 g 和 f 很像
换句话说,我们把可能的 g 放在一个集合中,由机器学习演算法挑选出最合适的 g。如下图: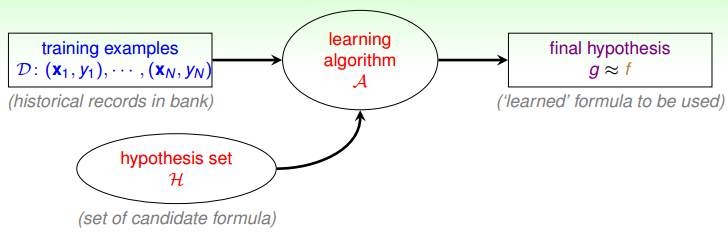
所以机器学习演算法有两个输入:资料和候选的 g
机器学习模型 = A + H
对机器学习更具体的定义: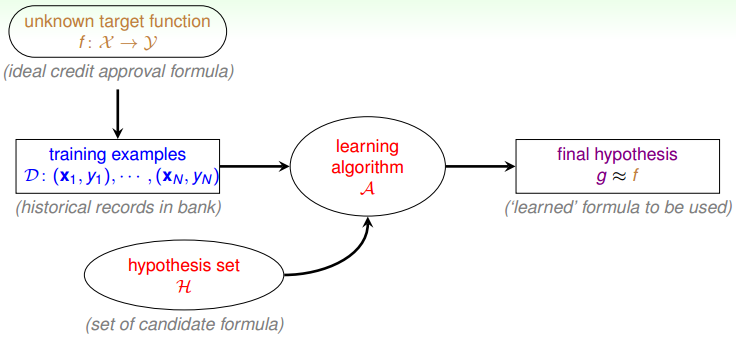
从资料出发,由机器学习演算法算出假说 g,我们希望 g 很接近 f
6 机器学习与其他领域关系
6.1 机器学习与数据挖掘
机器学习(Machine Learning,ML):希望用资料找出一个假说 g 与目标 f 很像
数据挖掘(Data Learning,DL):希望用(非常大量的)资料找出一些有趣有用的事情
所以,如果“有趣有用的事情”和那个“g”一样,那么 ML = DL
如果“有趣有用的事情”和那个“g”相关,那么 ML 和 DL 可以互相帮助
通常,传统意义上的数据挖掘希望在非常大量的资料中进行非常有效地计算
6.2 机器学习与人工智能
机器学习(Machine Learning,ML):希望用资料找出一个假说 g 与目标 f 很像
人工智能(Artificial Intelligence,AI):希望电脑做出一些智能行为
机器学习找出 g,可以进行预测,这是一个很智能的行为,从这个角度来说,ML 是实现 AI 的一种方法
6.3 机器学习与统计
机器学习(Machine Learning,ML):希望用资料找出一个假说 g 与目标 f 很像
统计(Statistics):用资料做一些本来不知道的推论
g 是一个推论,f 是一个不知道的东西,从这个角度来说,统计是实现 ML 的一种方法
统计更重视数学