1 根据地理编码数据创建 Google 地图应用
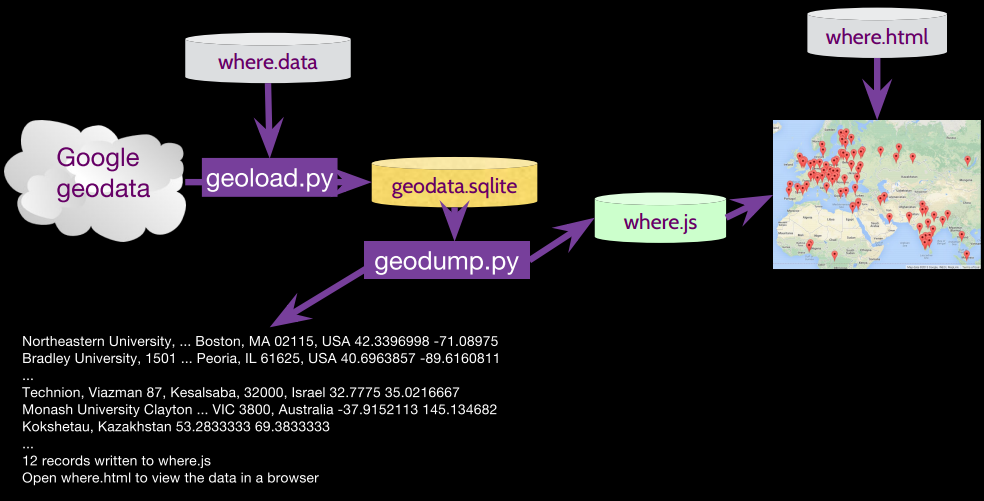
注意:例中所用所有完整代码可在这里查看
where.data:存放需要检索的地理位置
geoload.py:将地理位置与通过检索得到的数据信息放入数据库 geodata.sqlite
geodump.py:从数据库 geodata.sqlite 中读取数据并将 GPS 坐标和地名以 JSON 格式写入 where.js
geoload.py:
1 | import urllib |
geodump.py:
1 | import sqlite3 |
2 PageRank[^1]
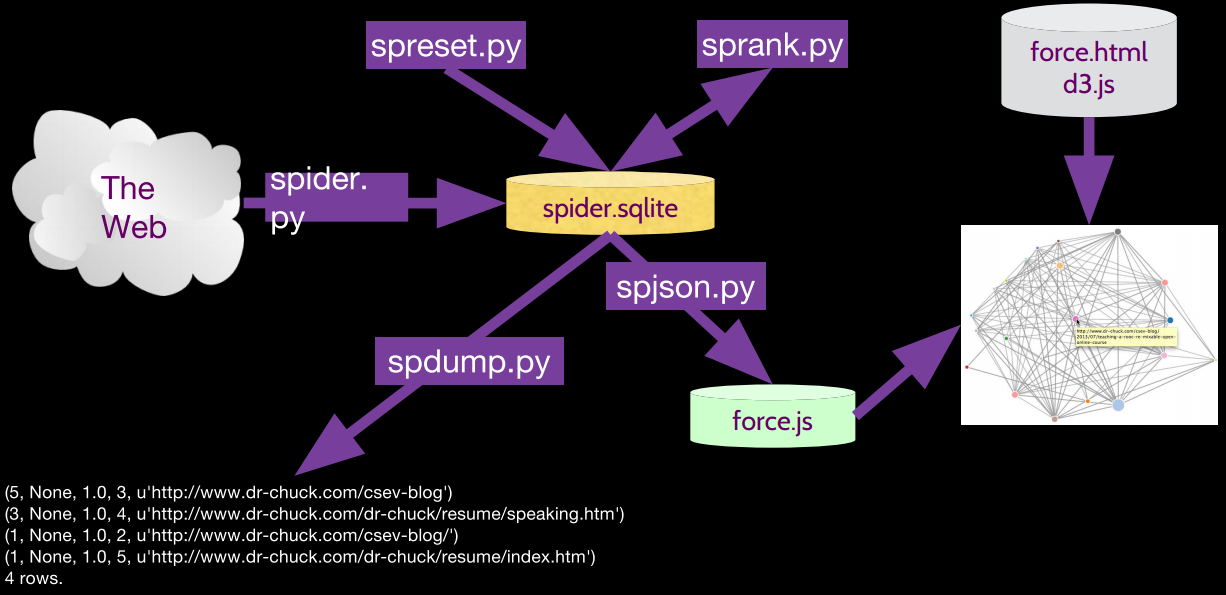
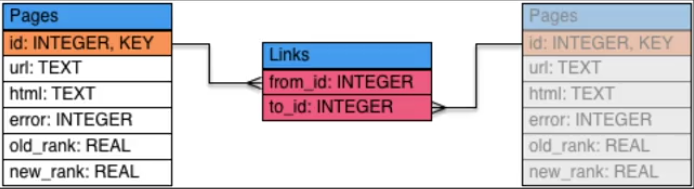
Pages之间是多对多的关系(如果 a 页面中有 b 页面的链接,那么 a 页面是 from_page,b 页面是 to_page),所以所以中间添加一张连接表
简化后的表:
[^1]: Google 创始人 Larry Page 和 Sergy Brin 关于 PageRank 算法早期思想的论文 《The Anatomy of a Large-Scale Hypertextual Web Search Engine》http://infolab.stanford.edu/~backrub/google.html