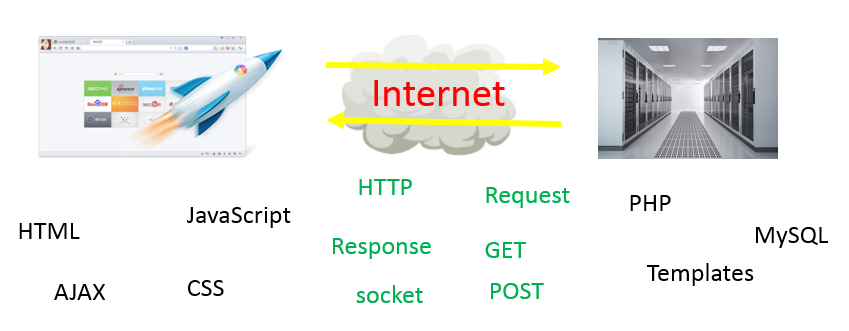
1 网络编程
1.1 套接字(Sockets)
Python内置对TCP套接字的支持。例如:
1 | import socket |
1.2 urllib
网页通过urllib.urlopen打开后,就可以把它当做一个本地文件进行读取。例如:
1 | import urllib |
程序结果:
1 | data--- |
- urllib.urlencode:把key-value这样的键值对转换成“key1=value1&key2=value2”的形式。例:
1
2
3
4
5
6from urllib import urlencode
data = {
'a': 'test',
'name': '中国'
}
print urlencode(data) # 打印出“a=test&name=%E4%B8%AD%D5%9B%BD” - urllib.quote:只对一个字符串进行urlencode转换。例:
1
2from urllib import quote
print quote('中国') # 打印出“%E4%B8%AD%D5%9B%BD”
1.3 使用BeautifulSoup解析HTML
需要将BeautifulSoup.py和代码放在同一文件夹下
1 | import urllib |
程序结果:
1 | Enter - http://www.dr-chuck.com/page1.htm |
2 可扩展标记语言 XML
- XML 术语:
- 标签(Tags):指示元素的开始和结束
- 属性(Attributes):XML里opening tags的键值对
- 序列化 / 反序列化(Serialize / De-Serialize):在程序中将数据转换成可存储或传播的通用格式。相反的过程又称为反序列化。
- XSD:描述XML文档的结构。可以用来检查该XML文档是否符合其要求。例:
XSD约束:可以通过检查的XML文档:1
2
3
4
5
6
7
8<xs:element name="person">
<xs:complexType>
<xs:sequence>
<xs:element name="full_name" type="xs:string" minOccurs="1" maxOccurs="1" />
<xs:element name="child_name" type="xs:string" minOccurs="0" maxOccurs="10" />
</xs:sequence>
</xs:complexType>
<xs:element>1
2
3
4
5
6
7<person>
<full_name>Tove Refsnes</full_name>
<child_name>Hege</child_name>
<child_name>Stale</child_name>
<child_name>Jim</child_name>
<child_name>Borge</child_name>
</person> - XSD 数据类型。例:
XSD约束:可以通过检查的XML文档:1
2
3
4
5<xs:element name="customer" type="xs:string"/>
<xs:element name="start" type="xs:date"/> <!-- data类型-->
<xs:element name="startdate" type="xs:dateTime"/> <!-- dataTime类型-->
<xs:element name="prize" type="xs:decimal"/> <!-- decimal(小数)类型-->
<xs:element name="weeks" type="xs:integer"/> <!-- integer类型-->注:日期必须是1
2
3
4
5<customer>John Smith</customer>
<start>2002-09-24</start>
<startdate>2002-05-30T09:30:10Z</startdate> <!-- 日期后面跟字母‘T’,时间后面的字母代表时区,字母‘Z’代表常见的UTC或者GMT(因为服务器常常分散在各地)-->
<prize>999.50</prize>
<weeks>30</weeks>4位数-2位数-2位数 - enumeration
1
2
3
4
5
6
7
8
9
10
11<xs:element name="Country">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="FR" />
<xs:enumeration value="DE" />
<xs:enumeration value="ES" />
<xs:enumeration value="UK" />
<xs:enumeration value="US" />
</xs:restriction">
</xs:simpleType>
</xs:element> - 数值数据类型
| 名称 | 描述 |
|---|---|
| byte | 有正负的 8 位整数 |
| decimal | 十进制数 |
| int | 有正负的 32 位整数 |
| integer | 整数值 |
| long | 有正负的 64 位整数 |
| negativeInteger | 仅包含负值的整数 ( .., -2, -1.) |
| nonNegativeInteger | 仅包含非负值的整数 (0, 1, 2, ..) |
| nonPositiveInteger | 仅包含非正值的整数 (.., -2, -1, 0) |
| positiveInteger | 仅包含正值的整数 (1, 2, ..) |
| short | 有正负的 16 位整数 |
| unsignedLong | 无正负的 64 位整数 |
| unsignedInt | 无正负的 32 位整数 |
| unsignedShort | 无正负的 16 位整数 |
| unsignedByte | 无正负的 8 位整数 |
- XML 解析:利用 XML 解析器 ElementTree,调用fromstring将XML的字符串表示转换为一棵XML节点树。例:运行结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import xml.etree.ElementTree as ET
input = '''
<stuff>
<users>
<user x="2">
<id>001</id>
<name>Chuck</name>
</user>
<user x="7">
<id>009</id>
<name>Brent</name>
</user>
</users>
</stuff>'''
stuff = ET.fromstring(input)
lst = stuff.findall('users/user')
print 'User count:', len(lst)
for item in lst:
print 'Name', item.find('name').text
print 'Id', item.find('id').text
print 'Attribute', item.get('x')1
2
3
4
5
6
7User count: 2
Name Chuck
Id 001
Attribute 2
Name Brent
Id 009
Attribute 7
3 JSON
- JSON将数据表示为列表和字典的嵌套。
例 1:字典运行结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import json
data = '''{
"name" : "Chuck",
"phone" : {
"type" : "intl",
"number" : "+1 734 303 4456"
},
"email" : {
"hide" : "yes"
}
}'''
info = json.loads(data) # info是个字典
print 'Name:',info["name"]
print 'Hide:',info["email"]["hide"] # info["email"]也是个字典例 2:列表1
2Name: Chuck
Hide: yes运行结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import json
input = '''[
{ "id" : "001",
"x" : "2",
"name" : "Chuck"
} ,
{ "id" : "009",
"x" : "7",
"name" : "Chuck"
}
]'''
info = json.loads(input) # info是个列表,列表里的元素是字典
print 'User count:', len(info)
for item in info:
print 'Name', item['name']
print 'Id', item['id']
print 'Attribute', item['x']1
2
3
4
5
6
7User count: 2
Name Chuck
Id 001
Attribute 2
Name Chuck
Id 009
Attribute 7 - json.dumps:将数据从 Python 原始类型转化为 JSON 类型。例:运行结果:
1
2
3
4
5
6import json
obj = [[1,2,3],123,123.123,'abc',{'key1':(1,2,3),'key2':(4,5,6)}]
encodedjson = json.dumps(obj)
print repr(obj)
print encodedjson具体的转化对照:1
2[[1, 2, 3], 123, 123.123, 'abc', {'key2': (4, 5, 6), 'key1': (1, 2, 3)}]
[[1, 2, 3], 123, 123.123, "abc", {"key2": [4, 5, 6], "key1": [1, 2, 3]}]
| Python | JSON |
|---|---|
| dict | object |
| list,tuple | array |
| str,unicode | string |
| int,long,float | number |
| True | true |
| False | false |
| None | null |
| 可选参数: |
sort_keys:对dict对象进行排序,(默认dict是无序存放的)。例:
1
2
3
4
5
6
7
8
9
10
11
12import json
data1 = {'b':789,'c':456,'a':123}
data2 = {'a':123,'b':789,'c':456}
d1 = json.dumps(data1,sort_keys=True)
d2 = json.dumps(data2)
d3 = json.dumps(data2,sort_keys=True)
print d1
print d2
print d3
print d1==d2
print d1==d3运行结果:
1
2
3
4
5{"a": 123, "b": 789, "c": 456}
{"a": 123, "c": 456, "b": 789}
{"a": 123, "b": 789, "c": 456}
False
True在上例中,由于dict存储的无序特性,data1和data2无法比较。因此两者可以通过排序后的结果进行比较。
indent:缩进。例:
1
2
3
4
5import json
data1 = {'b':789,'c':456,'a':123}
d1 = json.dumps(data1,sort_keys=True,indent=4)
print d1运行结果:
1
2
3
4
5{
"a": 123,
"b": 789,
"c": 456
}separator:移除多余的空白符。例:
1
2
3
4
5
6
7
8import json
data = {'b':789,'c':456,'a':123}
print 'repr(data) :', len(repr(data))
print 'dumps(data) :', len(json.dumps(data))
print 'dumps(data, indent=4) :', len(json.dumps(data, indent=4))
print 'dumps(data, separators):', len(json.dumps(data, separators=(',',':')))运行结果:
1
2
3
4repr(data) : 30
dumps(data) : 30
dumps(data, indent=4) : 46
dumps(data, separators): 25
4 API
4.1 Google地理编码Web Service
例:
1 | import urllib |
运行结果:
1 | Enter location: Ann Arbor, MI |